寒芳 发布于2021-11-23
回复 2
浏览 972
14
今天是一个失败的案例,我用随机森林拟合股票月度收益率,测试集的平均AUC达到0.58,但回测时却一塌糊涂。
做法很直接,我选取了中证全指(000985.XSHG)作为股票池,使用巨宽的因子库,只选基本和动量两个分类,总共71个因子。训练集跨度为2006.1.1 – 2015.12.31, 测试集跨度为2016.1.1-2021.10.1, 测试集上预测的结果会用来做回测。
有些细节要强调一下,先说下X和Y的定义: 这里以月度为单位,label基于下个月的收益率(即:R(下月底)/R(本月底)-1)来计算,将收益率排序,top 30%为正样本,bottom 30%为负样本, X为本月底查得的因子。这样训练集的条数就约等于 月数 * 中证股票数 * 60%;再说下预测的逻辑,对股票池按月预测收益率的排序,然后可以算月度预测的AUC,再平均一下作为整体的预测效果。最后说下回测的逻辑,每月用预测的top 10%股票去调仓,等额度分配。
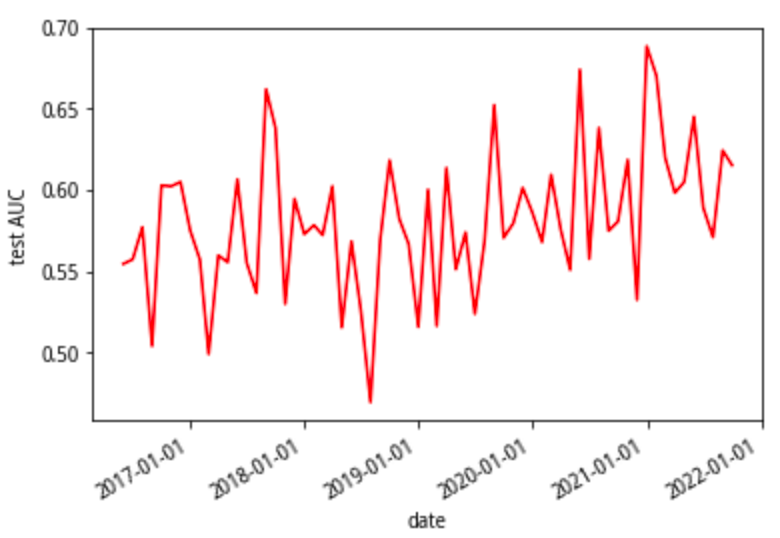
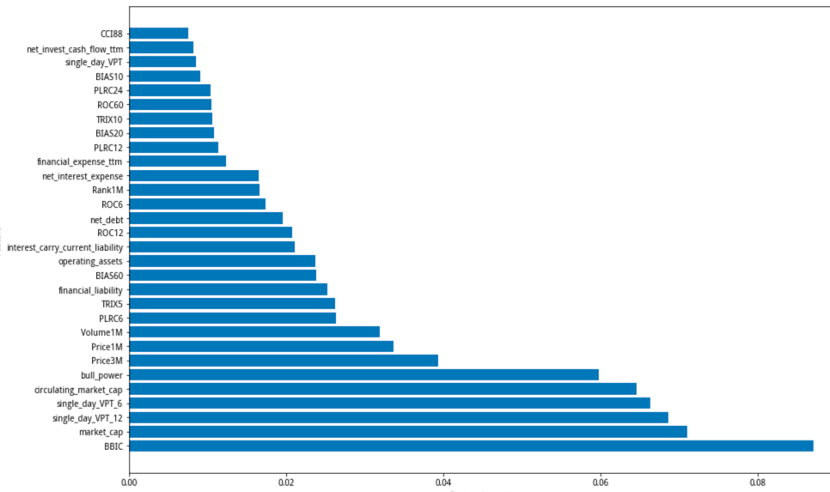
模型在测试集上的平均AUC 0.581,说明有一点区分度,区分度比社区里的这篇文章(https://www.joinquant.com/view/community/detail/a8f0764b797e8545754e01a5e01eb8fd)还要好一点。从feature importance 来看,前几位的特征依次是:BBIC(BBI 动量), market cap(市值),single_day_VPT_12(单日均价趋势12均值),single_day_VPT_6(单日均价趋势6均值),circulating_market_cap(流通市值),bull_power(多头力度)…,可见大多数都是技术面。这也符合预期, 因为预测的就是短期表现。
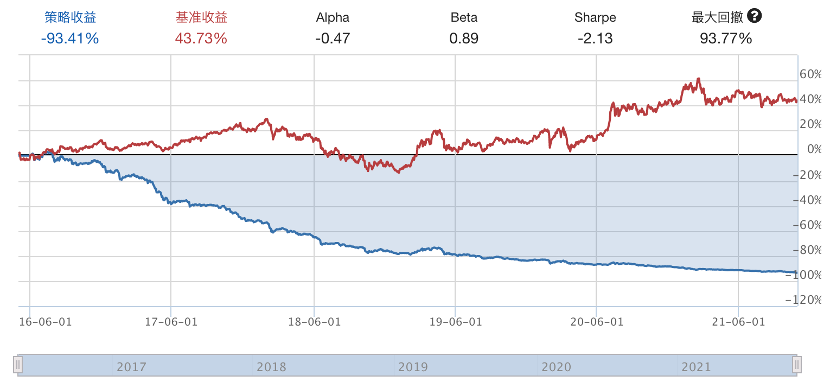
下边是比较悲惨的回测表现,我们首先拿预测的值来回测:
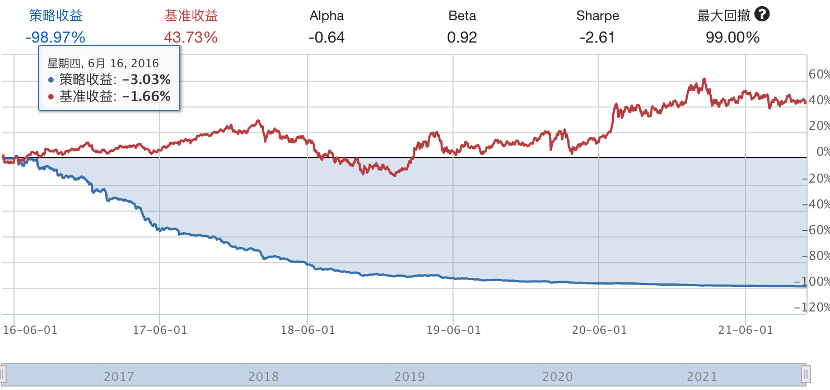
这也太差了吧,看了下调仓的股,变化很大,都不是什么好股。
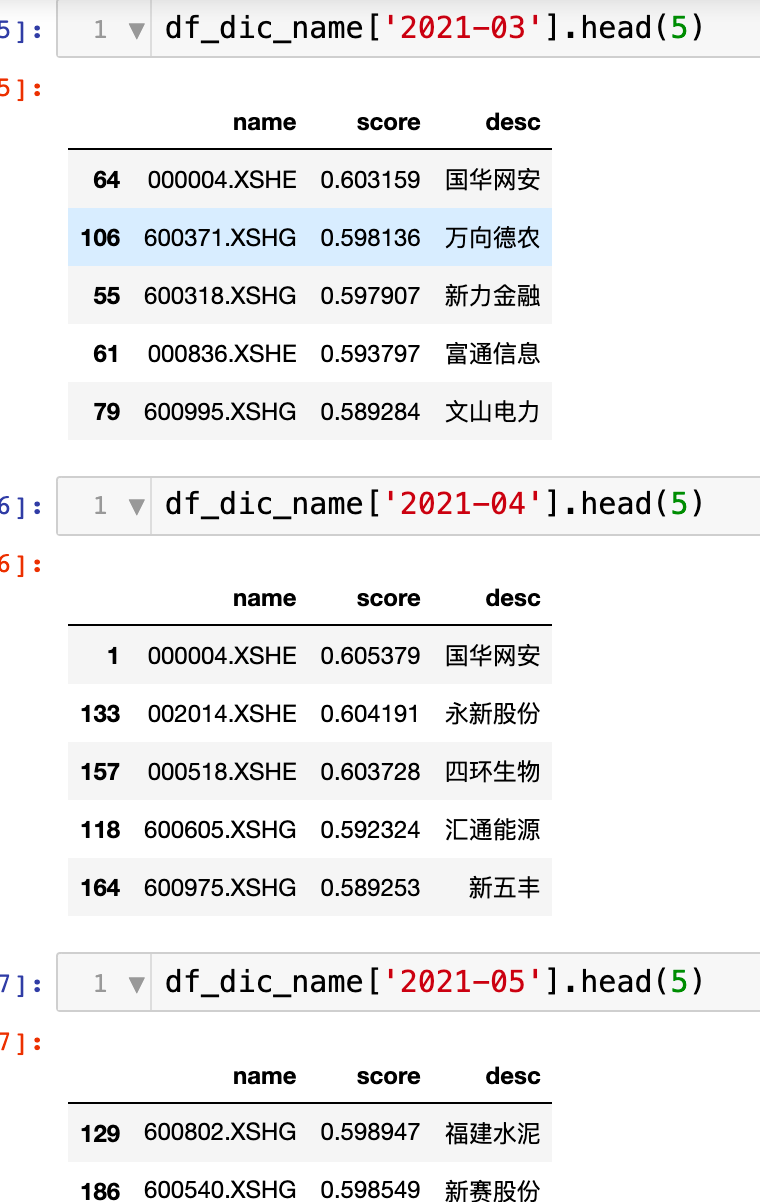
如果我们直接拿label做回测如何呢?即选取当月收益最大的10%股票,也不怎么样。同样调仓的股票乱七八糟。
所以模型还ok,但是回测很差的原因是什么呢?代码就是直接读结果文件,而且不同回测的结果也有区别,感觉不像是有bug。是不是以月度收益率作为目标本身就有问题呢?至少有这几个问题我没想通:
1. 像三因子、五因子的经典模型,最后要寻找的值是alpha,也就是截距项。而像本文这种拟合,是直接预测收益率,这里区别挺大的,能等效吗?
2. rf是非线性的,解释性是差于线性模型的。对于不能解释的因子,是不是风险很大?(这一点和非金融的机器学习比如搜广推有很大差别)
3. 是不是不能做空的机制也有影响?
希望大神们给些建议哈~~
评论
