rockff 发布于2023-06-27
回复 36
浏览 2248
87
股票出现涨停,特别是阶段性的向上突破涨停,是一个标志性的特征,涨停前的K线走势和形态,通常是吸引人研究的焦点,单从直觉上看,部分涨停股的K线具有相似的特点,或者说有着某种模糊的模式,值得进一步进行挖掘和研究。
AI机器学习,特别是深度学习,更擅长数据的感知和信息的提取,很适合对上述场景数据进行分析研究,也因其应用环境和方法简便,非常适合初学者由浅入深的学习。所以,作为一个初学者,通过聚宽量化课堂和社区文章入门的自学者,本文就是**对自己的一些想法和学习内容进行的一个简单验证和总结**,发布出来也是感谢平台和前人的无私分享。因本人水平所限,观点、方法或结论都可能存在错误,欢迎您指正交流。
主要过程如下:
**1,计划任务目标**:使用机器学习完成分类任务,目标分类两个:涨停和非涨停。假设K线形态数据对股票涨停具备一定的解释力,算法模型可以学习到了其中部分模式,并能在测试数据表现出一定的预测能力,预测的准确率可以说明之前自己的猜想有无道理,或者说假设是否成立(部分成立或完全不成立)。
也存在无法证明的情况:由于数据的原因、自己方法的问题,或者算法模型以及分析解读能力等各种原因,很有可能无法达成上面的目标,但无论如何,这是一种学习的过程,兴趣是最好的老师,动手做通常是最有价值的。
**2,数据准备**:首先对部分A股历史涨停数据进行甄别和标记,符合条件的涨停日被标记为1,不符合条件的涨停和非涨停日标记为0,作为对向标记。因为0数据的比例非常大,为了简化并让数据有代表性,最后的样本数据按照1:5的比例配比(1全部取出做样本,0按照5倍的比例随机抽取作为样本。选取点位可参看后面附图)。然后数值化样本时间点前N日的每日K线数据:对K线表示的涨跌幅,日内波动以及上下影线长度比例等进行测算,形成一个时间序列化的特征数据集;最后,为了方便进行特征和算法之间的对比,增加了一些非时间特征,比如基本的股本数据、jq的情绪和动量因子等。
最后应用的样本数据大小约110M,含900支股票约22000条数据;特征字段约290个,其中时间序列字段270个(每天生成9个字段,N=30天,即30✕9)。
**3,机器学习***:分别应用一些基本的数据处理和机器学习方法:包括数据标准化、主成分分析、决策树、随机森林,SVM以及深度学习的DNN、RNN(循环神经网络)进行建模、训练和调优,在单独划出的测试数据上进行模型的测试和对比验证等。
先给出**一个简单结论**:RNN表现出了最佳的预测能力;根据K线形态预测涨停的准确率显著大于常识水平。可以说最初的直觉是有一定道理的!
(说明:对于二分类任务,本测试更主要是对涨停--标记1--进行识别和预测,所以评价的主要依据是测试结果的混淆矩阵以及准确率/召回率,同时,由于样本是不平衡数据,目标1和0的比例是1:5,所以,若是随机判断分类准确率应该是1/6约16.7%;RNN模型对“1”的预测达到了26%的准确率和50%以上的召回率,可以说表现相当优秀。)
Confusion matrix:
[[2591 1137]
[ 354 394]]
precision recall f1-score support
0 0.88 0.70 0.78 3728
1 0.26 0.53 0.35 748
accuracy 0.67 4476
**关于数据标记:**
标记涨停点的范围选择的是中证500+中证1000范围内,做简单过滤后的股票池过去5年出现以涨停收盘的时间点,考虑到最初是以阶段性的向上突破涨停为主要研究目标,对涨停点进行了筛选,如有下述情况的筛掉不要:
1,检查涨停日后60日内,逐日的最大回撤-最大收益>10%;最终最大收益< 10%或60日平均收益< 0;
2,距离上一个涨停< 20日;
最后保留的涨停点数据标记为1。随后再按照1:5的比例随机选择其它数据标记为0。
以下面两个图的实例说明,红色是最后选用的涨停标记点1,绿色是随机选择的0标记点,蓝色是筛掉的不合要求的涨停点。
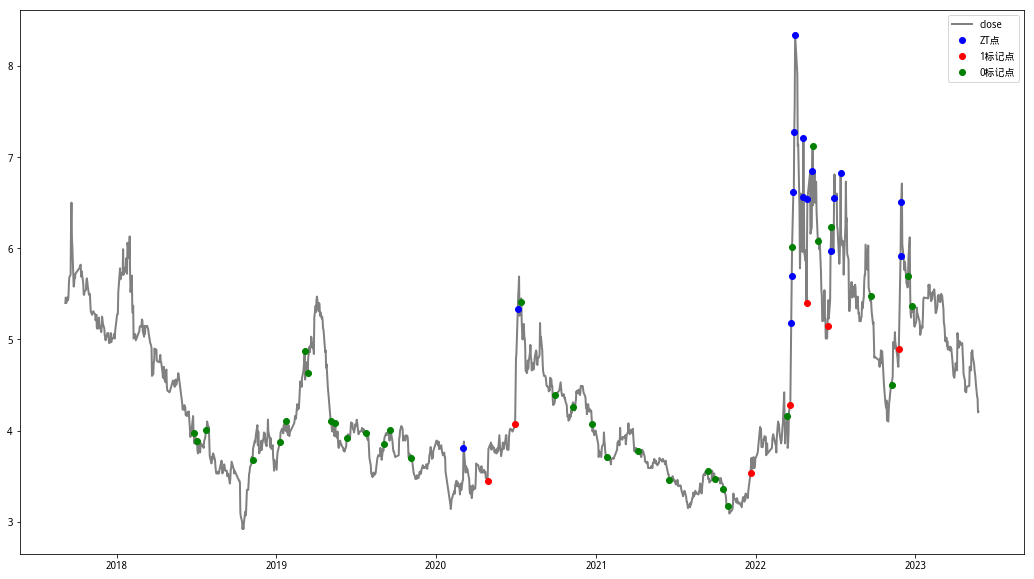

最后总共可以筛选出1809只股票,总共45636个样本数据。由于取出所有特征数据需要时间过长,从试验角度最后只选用了前900支股票约22000条样本数据。取数据用时约为3.5小时。
**关于K线形态数据:**
每天选取9条数据,包括每日收盘价,成交量,开盘和收盘涨幅,K线实体长度与上下影线长度以及与每日最高和最低价之间的相互比例关系,共9个字段代表K线的相对形态;部分数值数据取对数做非线性变换;
其它非时间序列以jq的因子数据为主,主要在主成分分析和决策树算法中考察特征的关系和重要性,没有特别的不再赘述。
代码较为初级,为了方便调试,最后是将数据下载到本地在自己本机的python环境下调试测试的,仅供参考。
深度学习方面和后继的思考总结随后再完善补充。
**6-29补充:**
趁热打铁把这个总结写完吧,主要想说的还有三个方面:
1,几种主要算法在测试集上的表现和个人感受
2,这项研究的不足及未完成的地方
3,对AI量化应用前景的个人浅见
运用相同的测试数据统计预测准确率,从高到低的排序依次是:RNN-DNN-SVM-决策树-随机森林。
前三个模型的得分比较接近,大约是26%、24%和22%的区别,而决策树和随机森林的得分都低于16.7%的基准概率,大概只有12%、13%上下。
这个结果应该算合乎情理,对于高维复杂数据,决策树和随机森林难以避免会出现过拟合或者欠拟合,不太适用本例的数据,而前三种算法则表现出处理高维复杂数据的模型能力;这三者之前的差异不大,我的理解主要在于数据集本身,机器学习中的数据是决定因素,当然,从算法角度看这个差异也是明显的,可以看出深度学习算法的巨大价值。
最后说明一点,这些测试更想是做一个定性的分析,所以没有进行很复杂的模型或超参的调优,只有一些基本的调优,所以数值上可能会有些出入,但结果应该是有一定可信度的。
不足的地方我想主要是两个,一是缺少对量化交易的考虑,没有收益回测,应该有简单的交易逻辑并完成基本的回测。二是先入为主用了分类任务进行机器学习,可以考虑设计回归任务,例如对5日或20日收益进行回归分析。这个有时间的话可以再搞一下。
结合学习中的一些体会,最后夹带发表点个人的想法,比较业余,希望大家能多交流:
1,前面提到,机器学习也好,AI量化或者其它AI应用也好,数据应该是第一位的,技术只是工具,核心还是业务场景中的数字数据,好的模型来自于好的数据和好的想法,所以个人感觉,个性化的指标、另类数据或者特征工程这些是值得多花时间的。
2、当前AI的话题很热,技术和平台也要不断迭代,个人比较看好深度学习技术的普及和强化学习、持续在线学习等技术的运用。最近看的书里有模仿OpenAI的Gym环境建立“金融沙箱”进行智能交易的尝试,感觉是打开了量化的设计和想象空间。如果您也有兴趣,希望一块学习和交流。
评论
Downloads/dfXY0614_900s_22000r_291c.csv,这文件在哪?
2023-06-28
多来点深度学习,多搞点运行策略,赞
2023-06-28
@huasmaple 本地的吧
2023-06-28
@huasmaple 可能是自己的因子
2023-06-28
感觉设计涨停相关的,最好是能获取到主力资金、仓位之类的因子,准确率应该能更高,因为本质是资金驱使的
2023-06-28
今天把总结补充完了,谢谢大家的支持!
2023-06-29
@健健不要做咸鱼~ 是的,只是作为一个不同角度的研究,如果要转成实用的策略还需要做大量的工作。
2023-06-29
@张大波 距离策略化还有不小距离,谢谢支持!
2023-06-29
@huasmaple 在研究环境生成数据文件然后下载到了本地。
2023-06-29
@rockff 其实我感觉还有一个比较关键的,就是前一日涨停后面涨停的几率也很高,预测的结果本身对未来预测就很有帮助,但往往这种连板实际交易买不到,买得到的大部分会被洗盘或者彻底烂板
2023-06-29
@sino_samsara 不敢当,共同学习
2023-07-01
这个一看,就是专业人士,科班出身。
2023-07-02






